从线性代数看“不可译”:为何有些词只能近似表达
—— 一种温和的数学式语言框架
作者:Marco Giancotti
原文:https://aethermug.com/posts/linear-algebra-explains-why-some-words-are-effectively-untranslatable
有一件事至今仍让我难以释怀:有些人坚信不存在所谓“不可翻译的词”。我之前写过一篇文章说明自己为什么不同意这种看法,但总觉得那个解释不够有力。我一直认为还可以用更扎实的角度来说明这个问题,只是当时没想起来。
现在我想起来了:要理解翻译的局限,你需要把语言看作有点像数学。听起来可能有点疯狂,但我认为语言翻译很像线性代数中的“变换基底”(change of basis)。
我之所以会做这种奇怪的联想,大概跟职业习惯有关。我的博士研究和第一份工作都与操纵航天器和太空岩石的位置与姿态有关,那段时间我几乎每天都在与向量、矩阵、参考系打交道。但我相信,即便不懂数学,也能看懂我的比喻。请继续往下读。
你可能对线性代数还有点印象,比如这种东西:
但别担心,即使不懂也没关系,我只需要提醒你一点点最基础的概念——而这部分恰好和语言非常相似。
在那些和数学较劲的日子里,我也在学日语。它让我着迷,既因为它在书写和口语之间那种美妙的“脱钩”,也因为它的许多独特小癖好。但我更早就被一个“元层面”的东西击中:把日语和其它语言互译,真的很难。
这两个兴趣并行到最后,我很难不把它们连在一起。差不多十年前,我就把这个想法搁在心里角落,一直没说出口,也许是怕别人觉得太离谱。不过如今大语言模型很流行,它们确确实实是把词和概念当成向量来用线性代数操作的。也许我的类比并不算太离谱。让我试着讲给你听。
向量的故事
和很多人的想象相反,向量不是“一串数字”,它是一种抽象对象,本身并没有固定的表达方式。
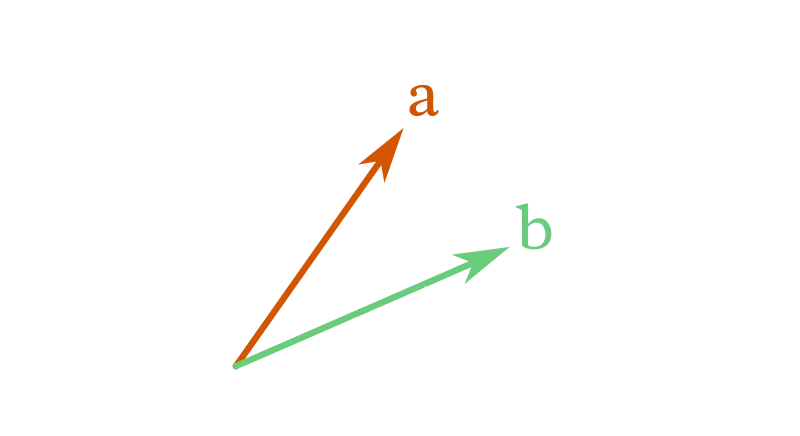
你可以把向量想象成漂浮在空间里的箭头,不涉及任何数字。
但仅仅是抽象的向量,基本没法用。我们需要一种写法,既好做代数计算,又好跟别人交流。做法就是选一个参照系——更准确说,选一组向量作为“基底”,用它来度量其它向量。
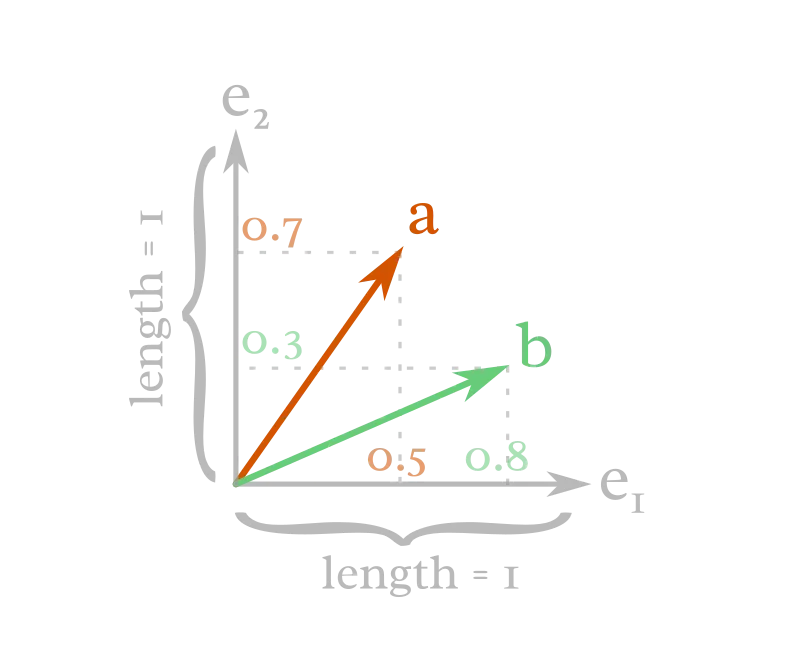
在二维的情况里,如果我们选两根向量(e₁ 和 e₂)作为基底,并规定它们长度为 1,那么就能用它们来比较并写出空间中所有其它向量的“坐标”。基底向量就像量尺。
这时数字才登场。把向量沿着基底做投影,就能给它们分配一串数字(在二维里,一串就是两个数):
这些数字就是该基底下向量的坐标。
例如,向量 a 可以表述为:“在 e₁ 的方向上,它的长度是 e₁ 的一半;在 e₂ 的方向上,它的长度是 e₂ 的 0.7 倍。”
我想强调也是你需要记住的最后一点“小数学”,是:如果你换一套基底,同一个向量会得到一组完全不同的坐标。
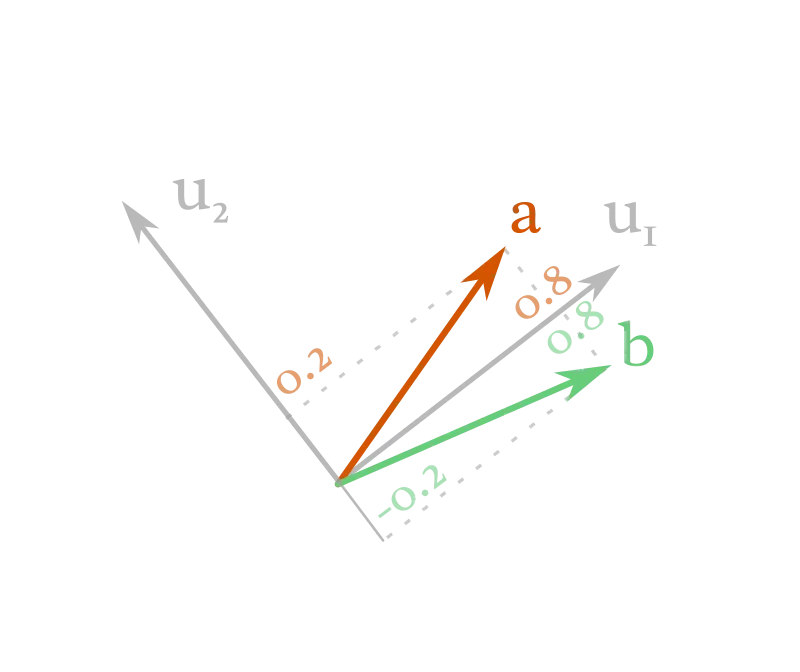
同样的向量,基底不同,数字也不同。
在这套新基底里,这两个向量的写法是:
也就是说,基底不同,坐标不同;但同一个抽象对象(那支向量)依旧是它自己。你可以用这两套坐标做同样的运算,比如改变向量长度与方向、计算两向量之间的夹角,最后都会得到相同的结果,因为你始终是在对同一个对象做事。从这个角度看,基底只是“外观问题”。
语言的故事
现在我们把视线转向语言,看看类比在哪里成立。
和很多人的直觉不同,“概念”并不是一个词或几个词的组合,而是你心里的一种抽象对象。
把我此刻心里那个概念,先画成一幅图,而不是用词。
但仅仅是抽象的概念,也不好用。我们需要写出来、用语法组织起来,才能操作和传达。做法就是选择一种和接收者共享的语言。
比如我脑子里的这个概念,如果用英语来表达,你会得到:
“Going to Tokyo”
这时词语登场了。把抽象的想法“投影”到英语的词汇与语法上,你就得到一串词:
这些词就是线性代数里坐标的对应物。严格说我刚才写得不够准确,因为它看起来好像英语只有三维(三个词),就像二维向量只有两个分量一样。实际上英语有几十万词,如果要“完整表示”,就需要同样长的一支“向量”,其中绝大多数位置都是空的。
英语提供了许多其它词,比如 camel、frolic、or,但在这个例子里,它们不需要出现,所以对应位置是空的,在“going to Tokyo”这次表达里就缺席了。
当然,和向量换基一样,你也可以在另一种语言里表达同一个概念。如果我选择意大利语作为“基底”,你会得到:
“Andare a Tokio”
概念还是同一个,只是它的“词坐标”换了:
外观并不只是外观
好,类比到此看起来相当直观。把所有语言都写成那样的“向量形式”当然会非常费墨水,也不适合日常使用。(大语言模型确实做了类似的事,但更曲折,也完全不可读。)
那它的意义在哪?因为世界上确实存在“不可翻译”的词。
所谓“不可翻译”,是指某种语言里有一个明确且广泛被理解的词,但另一种语言里并无精准等价物。我以前举过一些日语的例子,互联网上也有很多文章列举各语种里这类有趣的词。关键在于:在语言 A 里只需一个词的意思,到了语言B,往往要用一长串词才能勉强把它解释清楚。
我前面说线性代数里换基只是“外观问题”,因为对理想的向量而言,运算结果不会因基底不同而改变。但我们人类不那么理想——我们脆弱、会出错,有时还会“味儿不对”。
在下面两种表示之间,你更偏好哪一种?
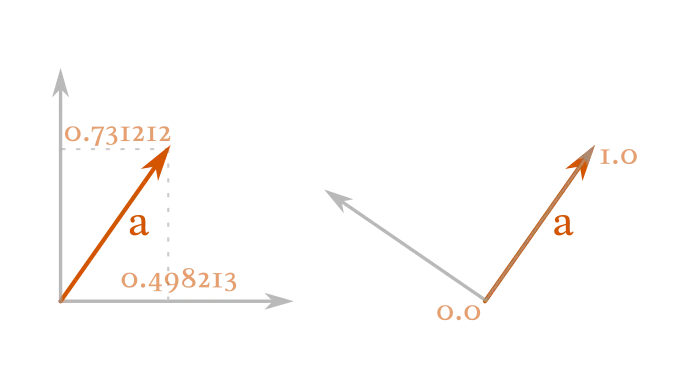
左:一般基底下,向量两分量都非零。右:在以它自身为基底之一的坐标下,坐标就是在 e₁ 上为 1、在 e₂ 上为 0。
理论上,两种表示完全等价。计算机不会偏好哪一个。但第二种“干净”的表示(一和零),不光更好记、更好懂,也更容易做数学。很多东西会因为乘以零而直接归零,乘以一也会简化,计算更快、出错更少。
这意味着,至少对我们脆弱的有机大脑而言,选哪套基底确实有差别。
语言也是如此。一个在英语里需要很多词的概念……
可以说,一个紧凑的词不但更便于表达,也更便于思考。这牵涉到著名的萨丕尔—沃尔夫(Sapir–Whorf)之争,不过我留到以后再谈。此处我只想说明它对“不可翻译”的意义,因为确实有人强烈否认这种现象。
翻译为什么会“失真”
我认为这个类比让“实践层面的不可翻译”几乎变得显而易见,理由至少有两条。
第一,沟通是有成本的,我们没有无限的时间与篇幅去放入所有需要的词。即使某个词理论上能在另一语言里被解释清楚,现实里也常常不值得那样做。
比如日语里的“物の哀れ(mono no aware)”,如果力求准确,英文可以展开成:
一种温柔、隐约的感伤或怆痛,源于对万物无常的敏锐体认;那种体认唤起细微而苦乐参半的哀愁,以及对其消逝的深沉而静默的共情。
放进词典也许可以。但词典不是翻译。翻译是要把整篇文本的意义传过去,你不可能给每个词都做这种多行扩展。
所以译者通常会把它压成核心,比如“万物之哀”。这能传达大部分意思,通常也够用了,但过程中确实丢掉了不少东西。
这和数据分析里的主成分分析(PCA)非常类似:只保留向量中最大的坐标,忽略其它分量。也就是选择更贴近目标向量的那几根基底,忽略剩下的,等于降维。译者每次“勉强接受”舍弃一些细微之处,就是在做某种 PCA——为了篇幅而割爱。
即便你愿意展开,用更多的词也会提高引入“副作用”的风险——那些额外词语自带的细微色彩会附加上来。这就像你选错了基底来做 PCA,导致坐标里混进很多小误差。比如前面的长译里用了“sorrow(哀伤)”,这个词在英语里会不会情绪太重?用了“passing(逝去)”,会不会让英语读者联想到人的死亡?
到最后你会遇到收益递减:越加词越让读者糊涂,而不是更清晰。
第二个问题是精度。即使你能用很多词、且这些词都不误导人,词汇仍然是有限的。和理想的数值坐标不同,语言里你只有有限的词可以选择来表达某一份意义。
设想你发现“subtle(微妙的)”在“…evokes a subtle, bittersweet…”里不够贴切。你确实想表达微妙,但觉得单说“subtle”有点太强了。你可以试着加副词弱化,比如“somewhat subtle”“slightly subtle”,但选项也就那么几个。万一都不合适呢?
某种意义上,语言是“量化”的:你可以从一个意义强度的台阶跳到另一个,但中间的连续状态无法表达。
这也是计算机的老问题。理想数字可以无限精细,而处理器里的数只能保留有限位数。你想要处理的理想向量
图上看起来像这样:
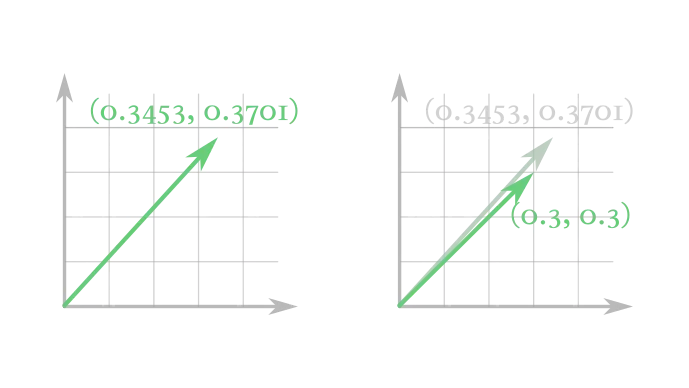
左:理想向量。右:如果计算机能存的最小增量就是网格线间距,那向量只能落在网格上。这就是精度损失。
(顺带一提,AI 工程师有时会主动把大模型“量化”压小体积,但模型会变笨,因为丢了很多细微之处。)
语言也是这样:每当我们把心里的概念落到词上,就被迫“降分辨率”。翻译文本里,这种降分辨率要发生两次:作者先把自己的想法写出来一次;译者再把已经降过一次的文本搬到另一种“量化台阶”不同的语言里。
读在字里行间
我希望这些在语言学与数学之间的非常规跳跃,能让你几乎直觉地接受:有些词和想法在实践中确实“难以翻译到位”。同时也别把这个类比看得太重,它走不太远。你也许会忍不住开始谈“词矩阵”之类的,但我不觉得那会帮你更明白。这类高阶的“概念线代”也许对大模型有用,却很难映射到人类能读懂、更别提能让你更智慧的东西上。
此外,语言还有一件数学里似乎没有的本事:什么叫“读懂字里行间”?
这很难准确定义,但我认为它和“结构”与“语境”有关——用词的布局以及所在的语境,会共同传达一些并不在任何单词里的意义。也许那是对“可忽略坐标”的巧妙利用——把词语那些边缘的、微小的细腻处散布在文本里,叠加起来,在读者心里产生集合效应。
一个真正懂行的译者,也许没办法把某个词或句子逐字逐义地完美对齐,但他可以在译文里“写在字里行间”,让那点不可译之处不再要紧。......
编辑留白
作者以线性代数的“基底”类比语言,说明概念是抽象向量,翻译是把它投到不同语言的词汇与语法上;某些母语词像“基底向量”在本语中干净利落,换到他语就不得不冗长拆解、做“主成分取舍”,难免丢细微并引入额外情绪色彩。
经管这更像是启发式的隐喻,而非严谨的语言学或数学模型(现实中的意义不只靠“词坐标”,还深受语境、文化、语用学、隐喻网络、叙事结构等影响,这些超出线性代数的框架)却极有解释力:语言的离散“台阶”与现实的篇幅效率约束,确实让“不可完全翻译”的现象普遍存在。
更重要的是,优秀译者的价值恰在于用结构与语境在“字里行间”补偿失真,把不可译之处化为可感之意。
延伸阅读
“沃尔夫假说(Sapir–Whorf hypothesis)”,又称为“语言相对论(linguistic relativity)”是关于语言、文化和思维三者关系的重要理论。
“语言相对论”指出:一个人所说的语言,会在一定程度上影响他对世界的理解方式和思维习惯。比如,不同语言在颜色、空间、时间上的表达各不相同,这些差异会让使用者在记忆、判断或描述这些事物时呈现出细微的认知差别。
强说法认为语言“决定”思维(现在基本不被接受);较弱的观点则认为语言“影响”思维(目前有不少实验支持)。举例来说:
- 有的语言更常用东南西北来描述方向,说这种语言的人在导航时更依赖绝对方位。
- 颜色词更细的语言使用者,在区分和记忆某些颜色时会更快或更准。
- 不同语言对时间的隐喻不同,也会影响人们估计时长或理解时间顺序。
语言像一副“认知眼镜”,会给我们看世界时增加一点偏色或焦距,但并不会把视野锁死。